




강화학습을 처음 접하는 학습자들 가운데 상당수는 MDP(Markov Decision Process)와 강화학습(Reinforcement Learning) 간의 개념적 차이와 관계를 명확히 이해하지 못해 학습 초기 단계에서 진입장벽을 경험하곤 한다. 이러한 혼란을 줄이기 위해서는 두 개념의 관계를 먼저 정리해볼 필요가 있다.
–
–
수학 이전의 강화학습 : 본능, 실험, 그리고 조건화
흔히 강화학습은 수학적 모델링에서 알고리즘 중심의 학문으로 가르켜지고 인식되지만, 실제로 그 이론적 기원은 수학이 아니라 당시의 직관적이고 실험적인 심리학과 신경과학에 깊은 뿌리를 두고 있다.
본 시리즈의 두 번째 글에서는 강화학습 이론의 기반이 된 몇가지 초기 심리학 실험들을 조명하면서, 강화학습의 핵심 개념이 어떻게 형성되었는지를 살펴보는것으로부터 강화학습에 대한 탐구를 시작해보고자 한다.
—
1. Edward Thorndike – 퍼즐 박스(Puzzle Box)와 시행착오 학습
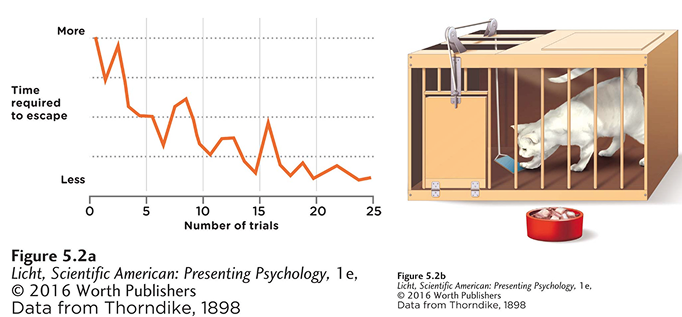
Thorndike는 고양이를 가두어 놓은 상자에서 레버를 당겨 탈출하는 시간을 측정하며, 시행착오(trial‑and‑error)에 기반한 학습 과정을 실험했다. 시간이 흐를수록 고양이의 탈출 시간은 점점 짧아졌고, 이는 S자 형태의 학습 곡선으로 나타나게 되는 것을 발견했다. 그는 이를 바탕으로 보상에 의해 행동이 강화된다는 효과의 법칙(Law if Effect)을 제안했으며, 이후 이 개념은 강화학습에서 ‘reward’ 메커니즘의 기초가 되었다. 이 시점에서는 수학적 모델링은 전혀 개입되지 않았다.
–
–
–
2. Ivan Pavlov – 고전적 조건형성(Classical Conditioning)
Pavlov는 개에게 음식을 제시할 때마다 종소리를 들려주는 방식으로, 중립 자극이었던 소리가 점차 침 흘림이라는 반사적 반응을 유발하게 되는 현상을 관찰했다. 반사적 행동(침 흘림)을 유발하는 무조건 자극(음식)이 종소리 같은 중성 자극과 반복적으로 연결되면, 결국 종소리만으로도 침을 흘린다는 사실을 밝혀낸 것이다 .
이는 외부 자극과 생리적 반응 사이의 연결성을 입증한 실험이었으며, ‘조건자극 → 조건반응’의 구조는 훗날 강화학습에서 환경 상태(state)와 보상 기대(reward expectation)를 모델링하는 데 중요한 영감을 주었다. 이 역시 수학이 아닌 행동의 관찰로부터 비롯된 결과였다.
–
–

–
–
3. B. F. Skinner – 조작적 조건형성(Operant Conditioning)
Skinner는 쥐나 비둘기가 스스로 레버를 눌러 음식(보상)을 얻거나, 특정 행동을 억제하기 위해 처벌을 적용하는 실험을 통해, 행동의 발생 확률이 어떻게 조작될 수 있는지를 체계적으로 탐구했다. 그의 주요 저작 『The Behavior of Organisms』(1938)가 이 분야의 이정표이다.
그의 대표적인 실험 장치인 Skinner Box는 능동적 학습의 대표 사례로, 동물이 스스로 레버를 눌러 보상을 얻는 능동적 학습이 가능하다는 이 실험은 고전적 조건형성과 달리, 행동이 주도적으로 이루어지며, 보상(reinforcement)이 행동의 빈도에 영향을 준다는 점을 입증했으며, 이 구조는 오늘날 강화학습의 핵심 개념인 행동 선택(action selection), 정책(policy), 피드백 기반 학습(feedback learning)개념의 초석이 되었다. 이 시기 역시, 여전히 수학은 등장하지 않았다.
–

–
–
4. James Olds & Peter Milner – 뇌의 보상 회로 (Pleasure Center)
Olds와 Milner는 쥐의 내측 전뇌다발(septal area)에 전극을 삽입하고, 쥐가 스스로 레버를 눌러 해당 부위를 전기 자극하는 실험을 통해, 뇌가 보상을 처리하는 방식에 대한 신경과학적 증거(쥐의 뇌 특정 부위를 전기 자극하면, 쥐가 스스로 자극을 반복적으로 받으려는 행동을 보인다는 사실을 발견)를 제시했다. 이는 자연적 보상(음식, 성행위 등)과 유사한 동기 반응을 유도한 것이다. 이른바 ‘pleasure center’ 연구로, 뇌가 보상을 어떻게 인식하는지에 대한 신경과학적 실증이다. 이 또한 수학은 전혀 개입되지 않은 실험의 산물이었다.
Olds & Milner (1954) 논문은 “rat would continually press a lever in return for… brief pulse of electrical stimulation in the septal area 쥐는 계속해서 레버를 눌러 중격 부위에 짧은 전기 자극 펄스를 제공합니다.”라고 보고하였으며, 이는 뇌내 보상 시스템 작동의 최초 입증이다. 이는 보상이 뇌의 특정 회로에서 처리된다는 것을 시사하며, 쾌감과 동기 부여에 대한 신경과학적 연구의 시작이었다.
–

–
–
실험으로부터 얻을 수 있는 세 가지
강화학습(Reinforcement Learning, RL)은 오늘날 딥러닝과 결합해 인공지능의 핵심 영역으로 자리잡았지만, 지금까지 살펴본 초기의 연구와 실험으로부터 알 수 있듯이 그 근원은 놀랍게도 수학이 아닌 심리학적 직관과 생물학적 실험에서 비롯되었다. 컴퓨터 알고리즘 이전부터, 인간과 동물의 학습과 행동 변화를 설명하려는 시도들이 이어졌고, 이는 지금 우리가 알고 있는 강화학습 이론의 초석이 되었다. 이 네 가지 실험은 공통적으로 다음과 같은 세 가지의 통찰과 질문을 던진다.
–
–
수학과의 만남
당시엔 이러한 질문에 대한 해답이 실험적, 심리적 직관에 기반했지만, 이후 수학적 모델링을 통해 이 현상들을 정량적이고 체계적으로 설명하려는 시도가 본격화된다. 그 전환점이 바로 Markov Decision Process (MDP)이다. 이제 우리는 다음 단계로 나아가야 한다.
강화학습이 수학과 만났을 때, 즉 행동, 상태, 보상, 정책이라는 요소들이 형식적 모델로 구성되며, 에이전트가 어떻게 최적의 행동을 학습할 수 있는지 설명하는 수학적 언어가 등장한다.
다음 글에서는 이러한 개념적 전환의 중심에 있는 Markov Decision Process에 대해 다루며, 어떻게 강화학습이 수학적으로 정립되었는지를 살펴보고자 한다.
–
–

