




The reason I chose Reinforcement Learning (RL) as the first topic of this blog is due to my personal interest in RL, which has developed steadily on a different path from the recent explosion of interest in deep learning and LLM-based AI agents.
While those technologies draw a lot of attention, RL continues to evolve based on classical theories and still has a strong impact in the real world.
Another reason is that RL is being integrated into Exa-Solution, an AI-powered enterprise application developed as part of Exavion’s extended ERP system.
The goal of this RL blog series is to start from the history of reinforcement learning, analyze and organize its theories and major algorithms, and explore how they can be applied to real-world software.
A Brief History of Reinforcement Learning
Computers first appeared in the 1940s, and the spread of personal computers began in earnest in the 1970s.
In the 1950s and 1960s, early computer scientists and software engineers started asking whether machines that could perform calculations might also be made to think like humans.
At that time, there were two main research directions: one group focused on data-driven methods like classification and prediction, known as machine learning, while another group studied how agents could learn optimal behavior through trial and error—this was the foundation of reinforcement learning.
Research on RL started as early as the 1950s, in parallel with machine learning.
By the 2000s, most of the core theories and algorithms that form today’s RL framework had already been developed.
Later, RL experienced a major breakthrough again through its combination with deep learning.
Classical Reinforcement Learning
Most of today’s reinforcement learning algorithms are still based on the classical theories and structures developed before the 2000s.
These early algorithms were mainly implemented using tabular methods, where the values of states and actions were stored and updated in tables held in memory.
Due to the limited memory and computing power of that time, such algorithms were mostly restricted to theoretical research or lab experiments and were hard to apply in real-world scenarios.
However, the proposal of the idea of an optimal policy, which selects the best action through trial and error, helped RL begin to take shape as a formal theory.
The core idea of RL is very similar to how animals and humans learn through interaction with the environment.
To define and systematize this idea mathematically, Richard Ernest Bellman introduced the concept of the value function and proposed the Bellman equation to calculate it.
He also introduced a method called Dynamic Programming (DP) to solve the equation, which became the starting point of reinforcement learning theory.
The Bellman equation is built on a sequential relationship between actions, rewards, policies, and states.
This made it possible to model RL problems as Markov Decision Processes (MDPs), which can be solved using dynamic programming.
About 20 years later, in the late 1970s, another major development occurred with the introduction of Temporal Difference (TD) Learning.
TD Learning combined the strengths of Monte Carlo methods and Dynamic Programming, and became a core component of modern RL.
It laid the foundation for many of the algorithms that followed.
Understanding TD is essential for understanding reinforcement learning.
The Rise of RL with Deep Learning
In 1989, Chris Watkins proposed the Q-learning algorithm in his paper “Learning From Delayed Rewards.”
This algorithm is one of several methods under the TD learning framework and is a representative example of an off-policy algorithm.
In off-policy learning, the policy used to choose actions and the policy used to learn from those actions are different.
It means that one policy can be used to learn better actions, while another policy can be used for actual decision-making.
After 2000, deep learning began to show tremendous success, and neural networks were introduced into traditional table-based RL.
In 2015, Google DeepMind extended Q-learning by combining it with deep neural networks to create the Deep Q-Network (DQN).
They applied this to an Atari game, specifically a block-breaking game, and showed how an AI agent could learn to play the game without any human intervention.
This surprised the world and marked a new chapter for RL.
Later, Double DQN was developed to address the overestimation problem in Q-learning.
Google DeepMind then introduced AlphaGo, a model that combined the Reinforce algorithm with deep learning, and once again demonstrated the power of reinforcement learning to the world.
Deep learning helped RL overcome its previous memory limitations, making it possible to apply RL to real-world applications.
Since then, RL has been successfully used in areas such as Tesla’s autonomous driving, robot control systems, game agents, and industrial automation.
After 2017, deep reinforcement learning has become the new standard..
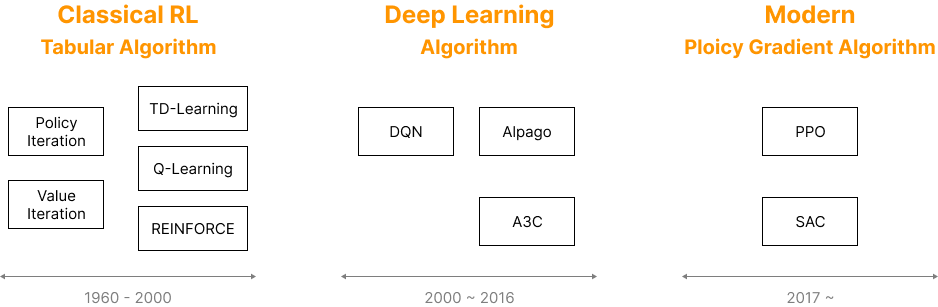
In 2016, DeepMind introduced A3C (Asynchronous Advantage Actor-Critic), another important milestone.
A3C is based on the Policy Gradient method.
While earlier RL algorithms mainly focused on approximating action-value functions to find optimal actions (as in Q-learning), after A3C, modern RL began to shift towards directly approximating the actions themselves using policy-based methods.
Most recent RL algorithms are built around the Policy Gradient approach, with Q-learning being used more as a supporting method.
This is a clear shift from the pre-2016 era, where Q-learning was dominant.
Since 2020, a large number of new RL papers have been published, and the field continues to evolve rapidly.
We can say that the golden age of reinforcement learning has now arrived.
Establishing and Spreading RL Theory
The foundation of reinforcement learning is the Bellman equation, which was developed to mathematically model sequential decision-making processes.
Bellman defined the RL problem using the structure of a Markov Decision Process (MDP), involving state, action, reward, and the next state.
To solve this, he introduced Dynamic Programming (DP), which later found wide application in many areas.
DP works by breaking down a complex problem into smaller sub-problems and solving them recursively.
For problems with recursive structure, DP becomes a very powerful tool.
Because of this, DP has become a fundamental technique not only in RL but also in many fields of computer science and industry.
Before the combination with deep learning, RL was seen as an interesting theoretical field, but it was limited in practical use due to memory and computation constraints.
In this context, Richard S. Sutton and Andrew G. Barto organized the scattered knowledge of RL into a systematic structure and published the book “Reinforcement Learning: An Introduction” in 1998.
This book became known as the bible of reinforcement learning, and every researcher studying RL had to read it.
In 2018, 20 years later, the second edition was published.
This marked the beginning of a new era where RL was being transformed by deep learning.
The second edition covers the entire RL field and is known for its mathematical depth and breadth of topics.
It remains a key reference in the field.
One of the most well-known figures in RL today is David Silver, a student of Sutton and Barto.
He led the AlphaGo project at DeepMind and played a major role in combining Q-learning with deep learning to master Atari games.
His RL course for graduate students at University College London (UCL) is still available online, along with slides, and continues to be used as a valuable learning resource by many researchers.
