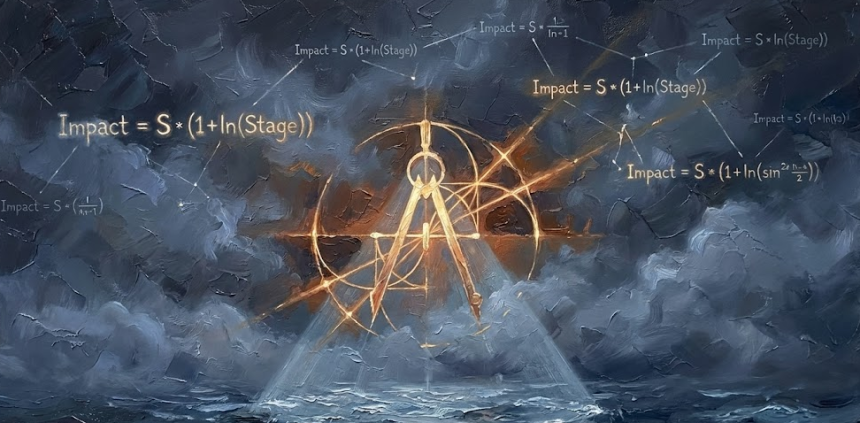
似然 (Likelihood)
本文是 [BA02. 贝叶斯推断] 销售的一双看不见的手:60 天赌局的第二部系列文章。如果说上一篇第一部“贝叶斯引擎:管理不确定性的数学炼金术”探讨了共轭先验分布和解析解的优雅,那么第二部将探讨作为证据数据的似然 (Likelihood) 计算,以及如何在数学上处理商业现场最具威胁的幽灵——“沉默 (Silence)”。
本文超越了单纯的销售管理,讲述了信息论 (Information Theory) 和统计权重设计如何结合以可视化迷雾中的风险,以及其内在的运作原理。
实际的商业现场,特别是销售或 SCM(供应链管理)的最前线,并不是像教科书那样数据如江水般流淌的地方。相反,那里是充满了匮乏、断绝以及“沉默 (Silence)”的空间。供学习的(大)数据不足,负责人因忙碌而经常错过录入,系统常常被搁置数日。
在今天的第二部中,我们将探讨 Exa 引擎的设计美学,它将该模型(正规化序贯贝叶斯推断:NSBI)的证据数据乃至“数据的空白”都翻译成数学风险。借用阿兰·图灵的统计直觉和信息论,公开“即使没有数据也能运作,越沉默越智能的系统”的数学基础。
1. 熵的时间函数:沉默不是“0”
商业中最危险的时刻不是听到坏消息的时候。反而是“没有任何消息的期间”变长的时候。如果无视并搁置这一点,将会犯下判断错误。
1.1 Time Kills All Deals:熵的增加
从信息论 (Information Theory) 的角度来看,在时间的流逝中没有新信息流入,这本身就是系统熵 (Entropy, 无序度) 正在增加的有力证据。“没有消息就是好消息”这句谚语在商业中很难通用。因为时间是扼杀所有交易的因素 (Time Kills All Deals)。
我们的模型不把这“沉默的时间”仅仅视为单纯的空白。而是通过数学上的“时间衰减 (Time Decay)”逻辑来计算风险。
1.2 数学实现:不确定性的扩展(方差的扩展)
如果在实务现场规定的时间内没有录入记录,每当时间流逝,引擎内部会微调增加贝叶斯分布的失败参数 β (Beta) 值。这在数学上是强制扩大概率分布的方差 (Variance) 的行为。
用公式定义如下:
$$\beta_{t+1} = \beta_t + (\lambda \times \Delta t)$$
这里 λ (Lambda) 是风险敏感度 (Decay Factor),Δt 是沉默的时间。
解释: 即使到昨天为止订单中标概率还稳固在 80%,如果今天没有任何互动就过了一天(或一定期间),系统会在明天早上自行通过数学方式蚕食那份确信。这是系统发给我们的警告。这是将“确信如果放任不管就会腐败”这一商业真理在数学上的实现。模型使图表在横向上变得扁平 (Flat),将沉默解释为“信任的磨损”,而不是“维持现状”。
2. 重量的几何学:韦伯-费希纳定律
同样的“积极信号”,例如拥有合同决策权的高管参加了会议这一事实,在所有情况下都具有相同的分量吗?在初次见面(第 1 阶段)见到决策者,和在最终合同就在眼前(第 5 阶段)见到,后者显然更具决定性且破坏力更大。
我们如何用数字控制这种微妙的“情境语境 (Context)”?单纯将阶段按 1 倍、2 倍、3 倍增加的线性 (Linear) 方式是危险的。因为系统可能会变得过于简单,或者在后期反应过于敏感而导致剧烈波动。
2.1 对数加权 (Logarithmic Weighting)
为此,我们将认知心理学的“韦伯-费希纳定律 (Weber-Fechner Law)”应用于模型。“人类的感觉对刺激的强度呈对数 (Log) 函数反应”的原理。商业阶段的重要性也同样不是呈几何级数爆发,而是画着对数曲线沉稳地增加,这样的反映更为妥当。
反映这一点的各阶段权重 (W) 公式如下:
$$W = 1 + \ln(Stage)$$
这里 Stage 是反映个别企业现场情况而定义的谈判 (Meeting) 阶段定义值。
根据该公式,例如探索阶段 (Stage 1) 的权重是 1.0 (1+ln1),但谈判阶段 (Stage 5) 的权重约为 2.61 (1+ln5)。即,在这种情况下,最后关头的一个信号被处理为比初期信号强大 2.6 倍的“决定性一击”。这是在数学稳定性 (Stability) 中实现了“不到结束就不算结束”的现场紧张感的结果。
3. 在没有数据的地方开路:启发式建模
在企业现场,为了数据科学而“存在充足的可供学习的(非结构化性质)过去数据”的案例相对罕见。但在这种情况下,模型依然发光。因为贝叶斯推断的优势在于即使在没有数据的情况下也能进行“合理推断”。
与其强行学习不完整的数据,我们选择了将资深专家的直觉移植到模型中的“启发式评分 (Heuristic Scoring)”。
3.1 启发式评分表 (Heuristic Score Table)
二战时期,阿兰·图灵收集少量的信息碎片,成功破解了德军的密码。比起信息的量,他更关注“信息的质量 (Quality)”,并将其确立为证据权重 (WoE) 的概念。
我们的模型继承了这一哲学,将商业现场发生的数万种情况压缩为核心信号,并以专家的视角将那“信息的密度”数值化。“启发式评分表”不是统计,而是反映现场经验和先验知识的定义 (Definition)。根据现场的独特性可以进行标准化,但在这里大致作为如下思路简略提出。
- 决定性肯定 (Strong Affirmation) 信号:预算确定、高管列席等成功迹象明显的信号。
- 主动抵抗 (Active Resistance) 信号:提及竞争对手、日程推迟等笼罩失败阴影的信号。
- 格局改变 (Game Changer) 信号:仅凭口头批准等单一信号就能颠覆整体概率的强力事件。
每个 Stage 和 Signal 都被分配了固有的分数值。收集到的 Signal 根据性质被分类为肯定 (α) 因素和否定 (β) 因素,置换为贝塔分布的参数,这根据贝叶斯逻辑立即反映在后验分布的概率中。这个评分表不是大数据分析的产物。相反,它是将“如果决策者参与,比实务人员确信度高 2 倍”这种现场智慧浓缩并固定为常数 (S<sub>score</sub>) 的结果。
4. 引擎的心脏:直觉与数学的结合 (似然:Likelihood)
现在让我们看看在贝叶斯引擎 (Exa) 的心脏中,这些要素在计算过程中是如何啮合在一起的。
在销售现场的系统(Mobile, Tablet, Laptop 等)中输入会议阶段 (Stage) 和作为会议结果捕捉到的信号 (Signal) 的瞬间,系统启动更新公式。
$$\text{Update Value} = S_{score} \times W_{stage}$$
将其扩展为整体冲击力公式,系统计算的最终冲击量如下得出:
$$\text{Impact} = S_{signal} \times (1 + \ln(Stage))$$
这就是我们在上一篇第一部中看到的计算证据数据(似然,Likelihood)的过程,这与先验分布结合,更新后验分布的概率。
蕴含在轻盈中的沉重
第二部的核心虽然矛盾,但在于“系统的轻盈”。
我们无需昂贵的 GPU 服务器或数年的数据清洗项目,只需结合现场经验和实务知识等人类直觉结合的仅两张表格(Stage 对数权重、Signal 启发式评分表)和数学原理,就能创造出最现实的企业环境推断引擎。
时间衰减公式 βt+1 = βt + (λ × Δt) 将我们从懒惰的乐观论中唤醒,
冲击力公式 Ssignal × (1 + ln(Stage)) 防止急躁的判断并捕捉决定性瞬间。
专家启发式用智慧填补数据的空白和沉默。
我们不是在黑盒中的魔法之上,而是在可解释且严格的数学逻辑之上建造房屋。
[下期预告:第 3 部]
下一次,是时候探讨将冰冷的统计概率 (Raw Probability) 转化为火热的商业决策的最后一块拼图,“决策校准 (Decision Calibration) 和 S 型曲线 (Sigmoid) 的美学”。